


The benchmark problem
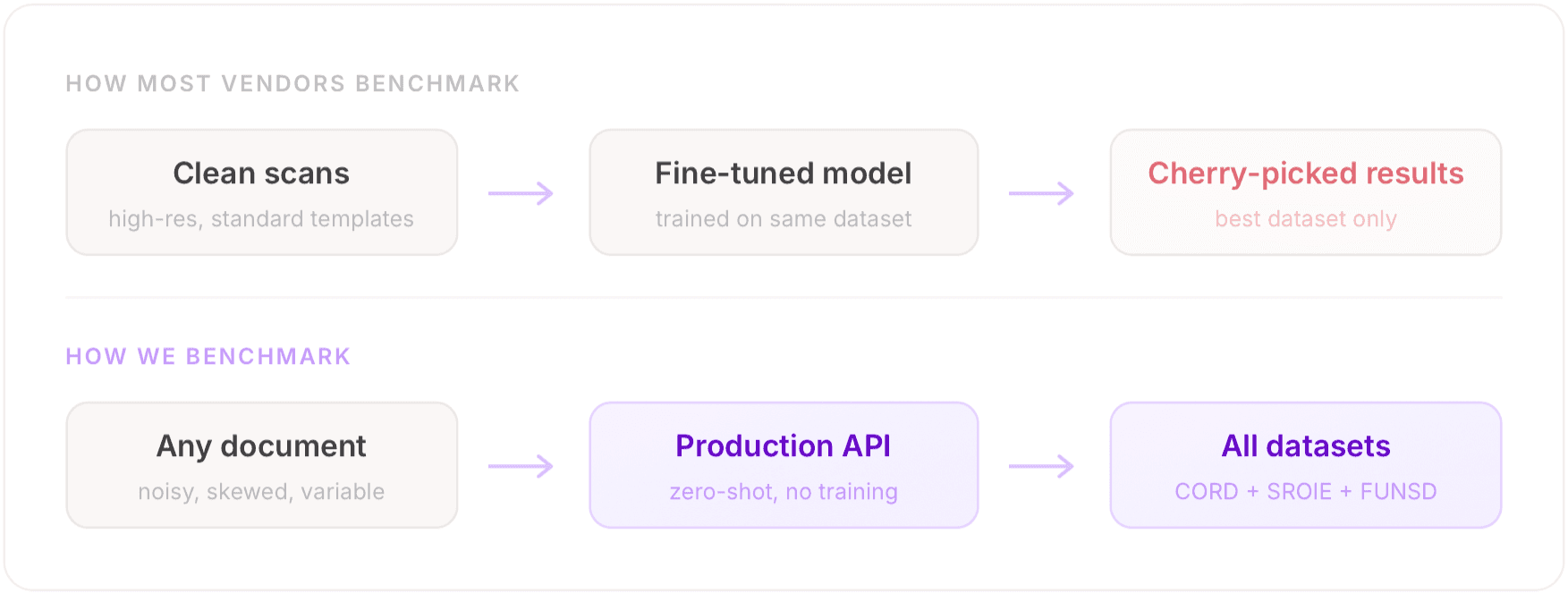
Many vendor benchmarks focus on controlled conditions that may not reflect real-world document complexity. They test on clean, well-lit scans of standard templates. They fine-tune on the training split and report on the test split. They cherry-pick the datasets where they win.
We aimed to evaluate performance under more variable, real-world conditions. We ran qomplement against four major competitors using our production API with zero task-specific training. No fine-tuning, no template configuration, no cherry-picking. Just schema-in, structured-data-out.
What we tested on
CORD is the easy one: structured receipts with predictable layouts. Any decent system should score well here. SROIE adds real-world noise: thermal printer artifacts, skewed angles, variable fonts. FUNSD is where things get brutal.
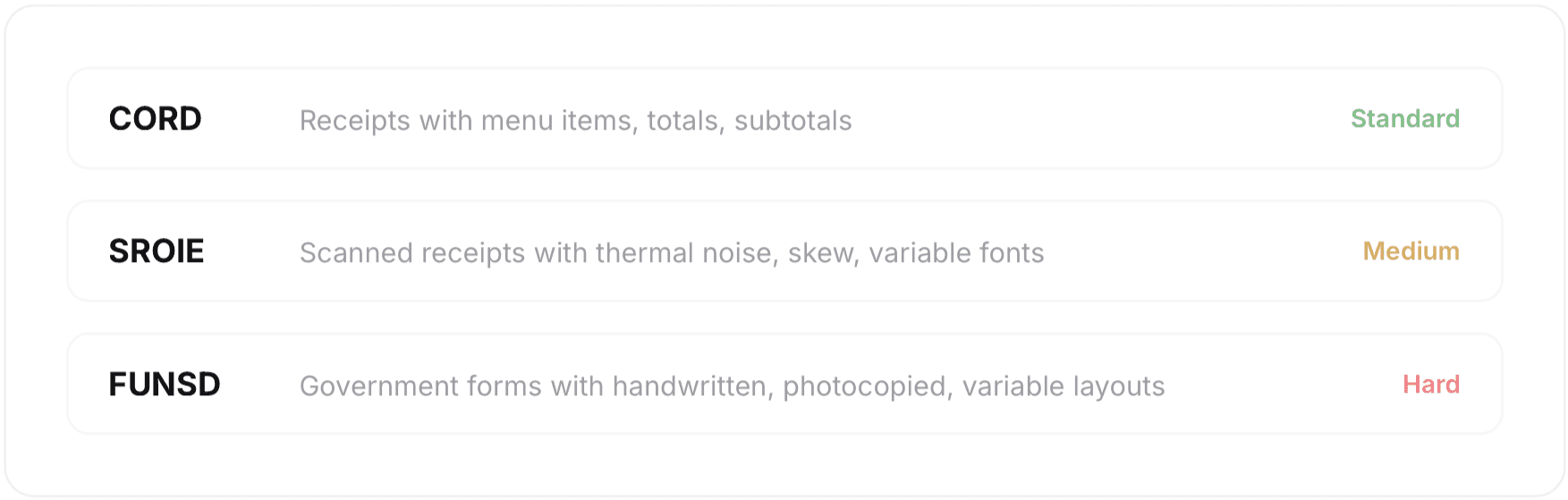
The reason FUNSD matters is that it's the closest proxy to what enterprise customers actually deal with: messy, inconsistent, high-stakes documents where mistakes cost money.
The results
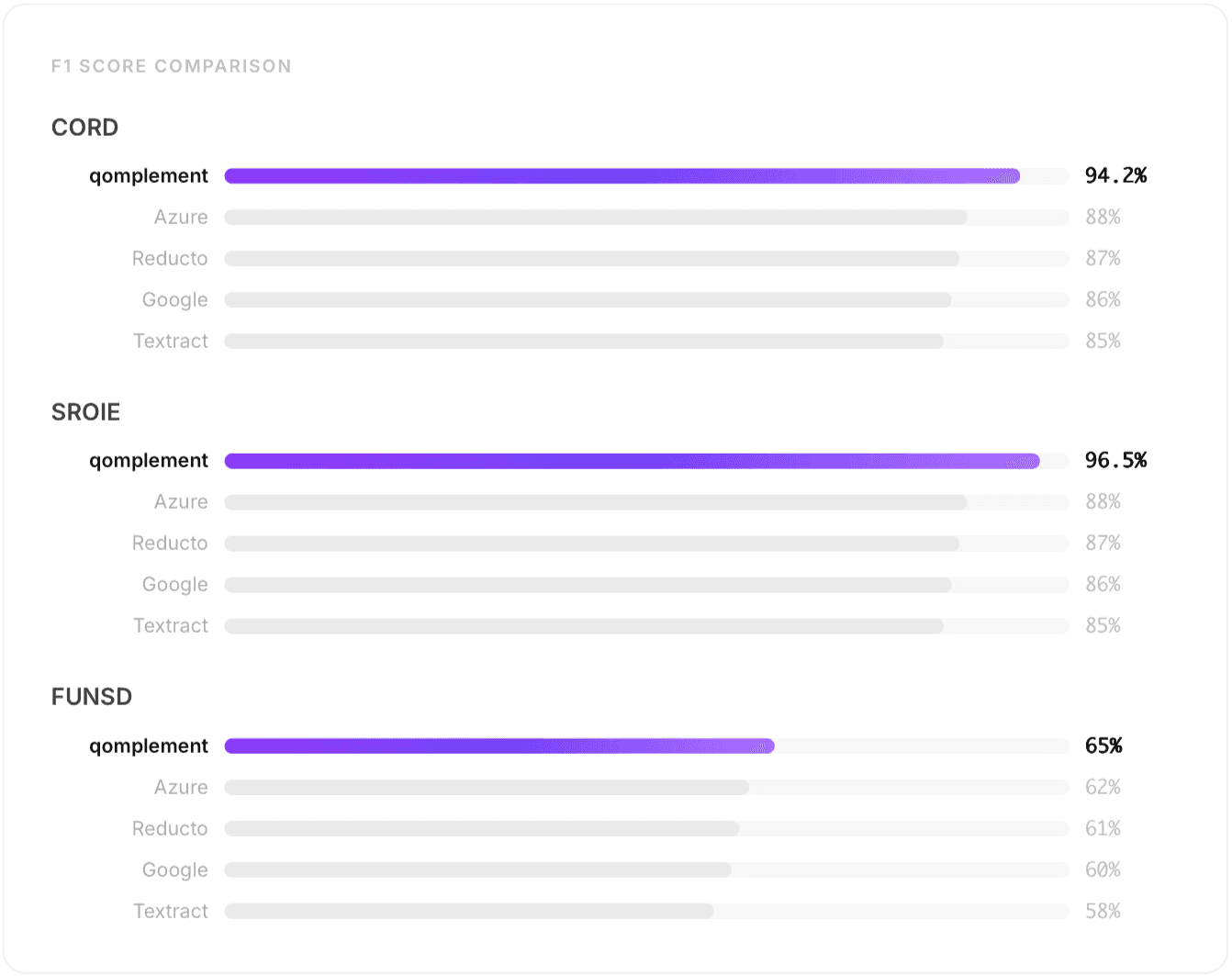
We observed a gap of 6–11 F1 points under these conditions. But the real story is what's behind these numbers.
In our evaluation, the systems we tested typically required some form of setup: Azure needs custom model training. Google requires processor configuration. Textract works best with predefined templates. Reducto optimizes for document parsing and chunking rather than field extraction. qomplement requires none of this. You send a JSON schema, attach your document, and get structured data back. The zero-shot nature of our approach isn't a limitation, it's the entire point.
Why single-pass extraction can struggle with complex documents
Most document AI systems treat extraction as a single-pass problem: OCR the text, maybe detect some layout regions, then try to map everything to fields in one shot. This works fine on clean receipts but can struggle with anything complex.

The problem is fundamental: a number next to the word "Total" means something different than the same number in a table cell under "Quantity." Single-pass models conflate these spatial and semantic signals. In some cases, errors may not be immediately visible, which can lead to incorrect field mappings in structured output that appears correct at first glance.
A $4,280.00 line item total mapped to "tax_amount" doesn't crash your system. It just corrupts your data. You discover it weeks later when the books don't balance.
Cascaded semantic decomposition
Our approach decomposes the problem into specialized stages that each solve a fundamentally different subproblem. We call it cascaded semantic decomposition.
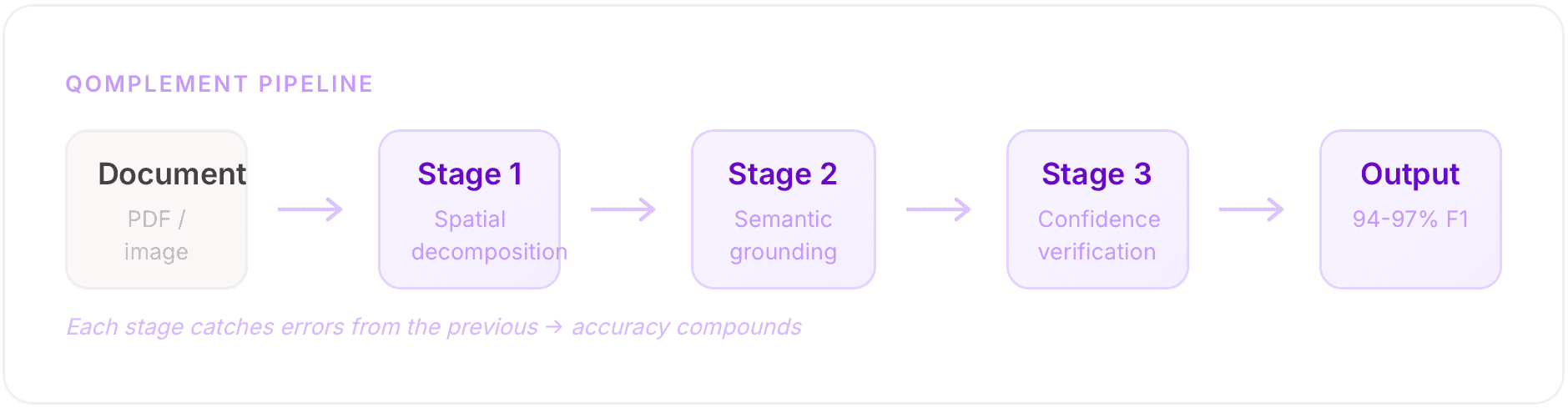
Stage 1: Spatial decomposition.
Identifies geometric relationships between text blocks, table cells, headers, and separators. This isn't traditional OCR, it's a learned spatial prior that understands document topology. It produces a spatial graph of regions with their geometric relationships.

Stage 2: Semantic grounding.
Uses vision-language reasoning to interpret what each region means in context. The spatial graph from Stage 1 provides the structural scaffolding; Stage 2 grounds each region to schema fields.

Stage 3: Confidence verification.
A calibrated uncertainty estimator that knows when it doesn't know. Uncertain fields get routed through a targeted re-extraction path that allocates more compute where it matters.
The result is an error profile that degrades gracefully rather than failing catastrophically. That's the property that matters in production.

A word on FUNSD
At 65% F1, you might think "that's not great." Consider the context: FUNSD is 199 noisy, photocopied forms with 31,000+ semantic entities across wildly variable layouts.
The published state-of-the-art (LayoutLMv3, fine-tuned on FUNSD's training split) hits ~92%. But that's a model that has memorized the specific field names and layouts of that exact dataset. Our 65% is zero-shot: we've never seen these documents before.
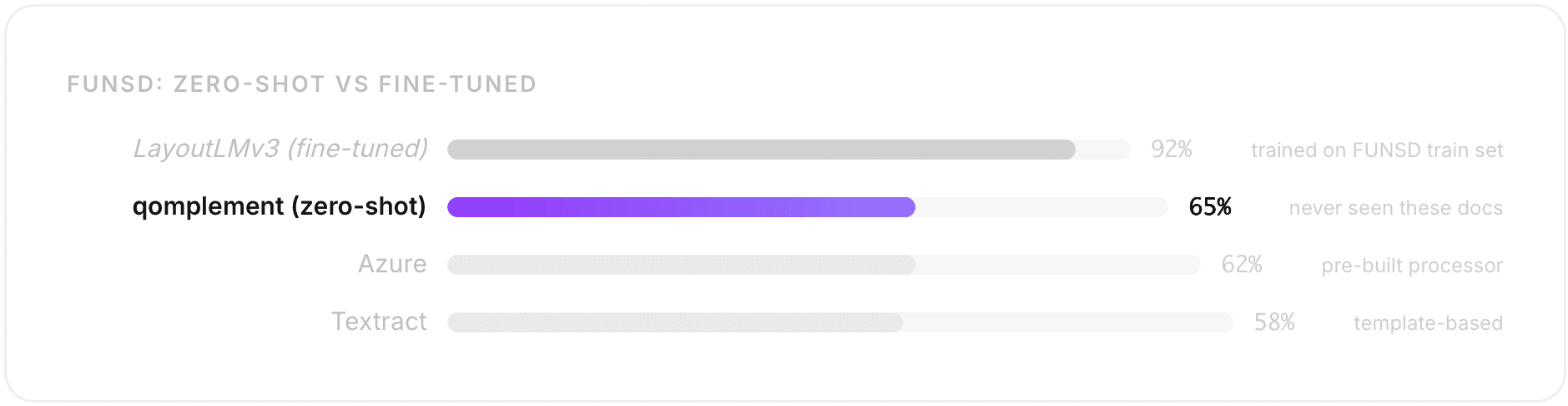
In a real enterprise deployment, you'd provide a schema with your specific field names, and accuracy jumps significantly. The FUNSD result demonstrates the property that matters in production: our architecture handles novel document types without catastrophic failure.
Methodology
Full test sets with no subsampling, no cherry-picking
qomplement: zero-shot via production /v1/extract API with JSON schema
Results are based on internal benchmarking using publicly available datasets and standardized evaluation methods. Competitor results are sourced from publicly available evaluations and may not reflect optimized or latest configurations. Actual performance may vary depending on use case, data quality, and system setup.
Metric: F1 Score, the harmonic mean of precision and recall, exact string match
No post-processing, no fuzzy matching, no normalization tricks
What's next
We're currently running OmniDocBench (1,355 pages, CVPR 2025) which tests the full spectrum: tables, mathematical formulas, multi-column layouts, figures with captions. We'll publish those results with the same transparency.
If you're evaluating document AI vendors and tired of seeing suspiciously perfect benchmark numbers, we'd love to run a head-to-head on your actual documents. No NDAs, no sandboxed demos, just your PDFs through our API.
We welcome independent replication of these results and are happy to run evaluations on real customer documents.